


Whitepaper: Architecture and Data Flow of the Calendar Invite Server for AWS
Introduction to the System
Managing and distributing calendar invitations at scale presents a significant operational challenge, requiring a system that is both robust and highly elastic. This whitepaper provides a comprehensive technical breakdown of the Calendar Invite Server for AWS, a serverless solution explicitly designed to address this challenge. The system is architected to handle high volumes of calendar data with efficiency and reliability.
The system's core operational concept is centered around a two-phase lifecycle for calendar data: the disassembly of incoming calendar invites into storable, componentized data, and their subsequent on-demand reassembly for distribution. By breaking down invites into their fundamental parts, storing them in a structured database, and reconstructing them only when needed, the architecture optimizes for both storage efficiency and dynamic delivery.
The objective of this document is to detail the serverless architecture, the end-to-end data flow, and the specific roles of key AWS services. It is intended for a technical audience seeking to understand and evaluate the system's design, processes, and capabilities.
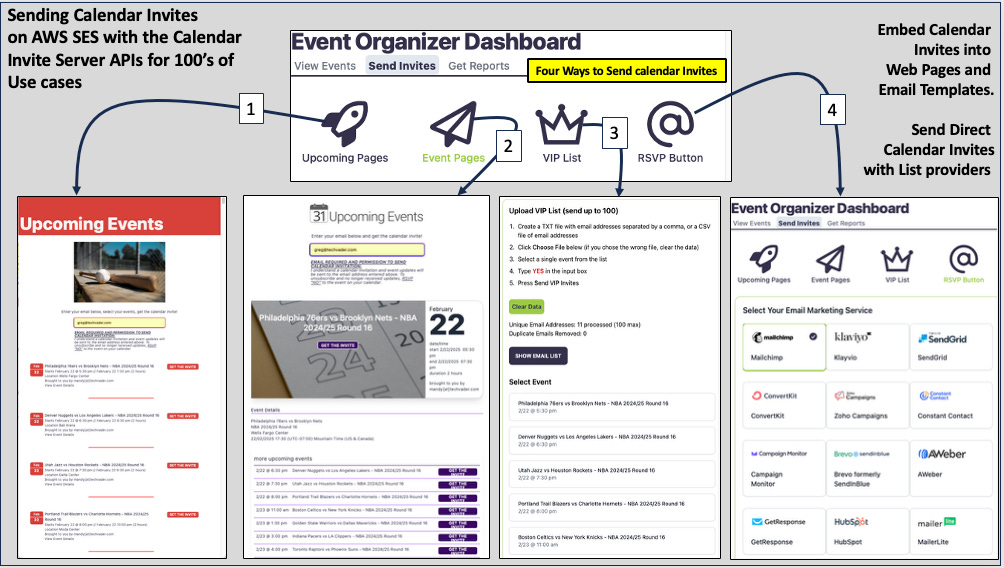
Core Architectural Components
The strategic decision to build the Calendar Invite Server on a decoupled, serverless architecture is fundamental to its design. This approach leverages a suite of managed AWS services to create a system that is inherently scalable, resilient, and operationally efficient, eliminating the need for traditional server management. Each service is chosen for a specific function, working in concert to process calendar data seamlessly.
The following table outlines the key AWS services employed in the architecture and their primary functions as described within the system's operational flow.
Key AWS Services and Their Roles
| AWS Service | Primary Function in the Architecture |
| SES (Simple Email Service) | Receives the initial incoming email containing the raw calendar invite data from an organizer. |
| SNS (Simple Notification Service) | Works in conjunction with other services to initiate the calendar invite disassembly process. |
| SQS (Simple Queue Service) | Participates in the messaging and triggering workflow that kicks off calendar data processing. |
| Lambda | Executes the core business logic, including the ETL process for disassembly and the on-demand reassembly of invites. |
| DynamoDB | Serves as the primary data store for componentized calendar data and tracking information, indexed by a Unique Identifier (UID). |
| S3 (Simple Storage Service) | Functions as a secondary storage layer where a copy of the system's data is maintained. |
| API Gateway | Provides the public-facing endpoints for the system's nine APIs, handling command triggers and receiving inbound tracking data. |
With this high-level overview of the established components, we can now examine the detailed process flow, starting with how data is initially ingested into the system.
Phase 1: Ingestion and Disassembly Workflow
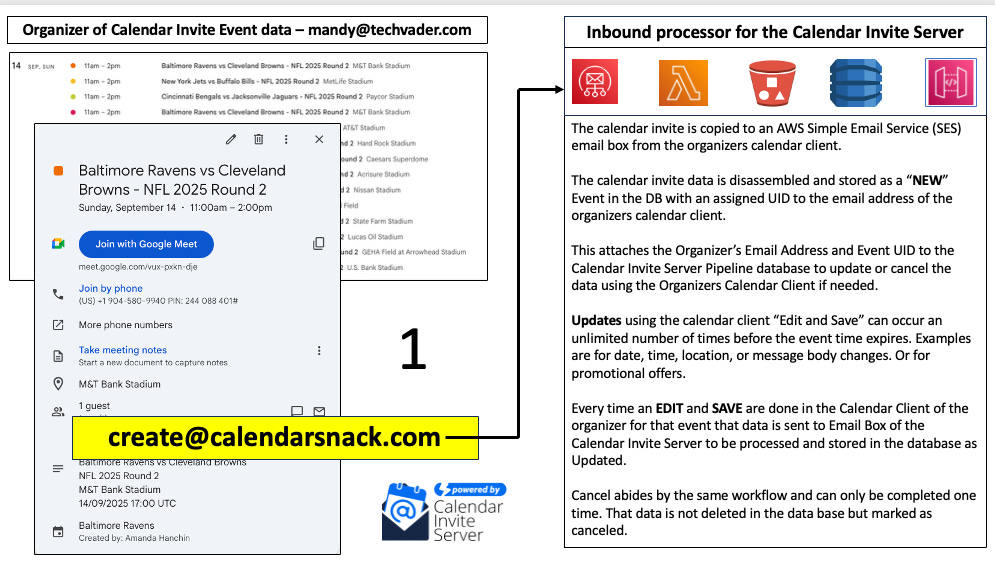
This section details the critical first phase of the process: how raw calendar invite data is ingested, processed, and prepared for storage. This workflow transforms an unstructured email communication into a structured, queryable dataset, laying the foundation for all subsequent operations. The step-by-step data flow is as follows:
Initiation: The process begins when an external event organizer sends calendar data to a pre-configured email address managed by the admin system administrator of the calendar invite server installation on an AWS account. (e.g., @
create.com). This address serves as the primary ingress point for all new event data for the domain from internal or external organizers who require Calendar Invite Codes. The email address for that mailbox name can be anything the organization wants.It can be a single address or multiple addresses for processing inbound calendar invite data for Calendar Invite Codes.
Reception: The AWS Simple Email Service (SES) is configured to monitor this address and receive incoming emails containing the calendar invitation.
Processing Trigger: Upon reception, the system utilizes a combination of Simple Notification Service (SNS) and Simple Queue Service (SQS) to trigger a Lambda function, initiating the automated disassembly of the new calendar invitation. This decoupled trigger mechanism ensures the system can handle bursts of incoming data gracefully.
ETL Operation: The invoked Lambda function performs an Extract, Transform, and Load (ETL) operation. It parses the raw calendar invite, extracts its fundamental components, and transforms them into a structured format suitable for database storage.
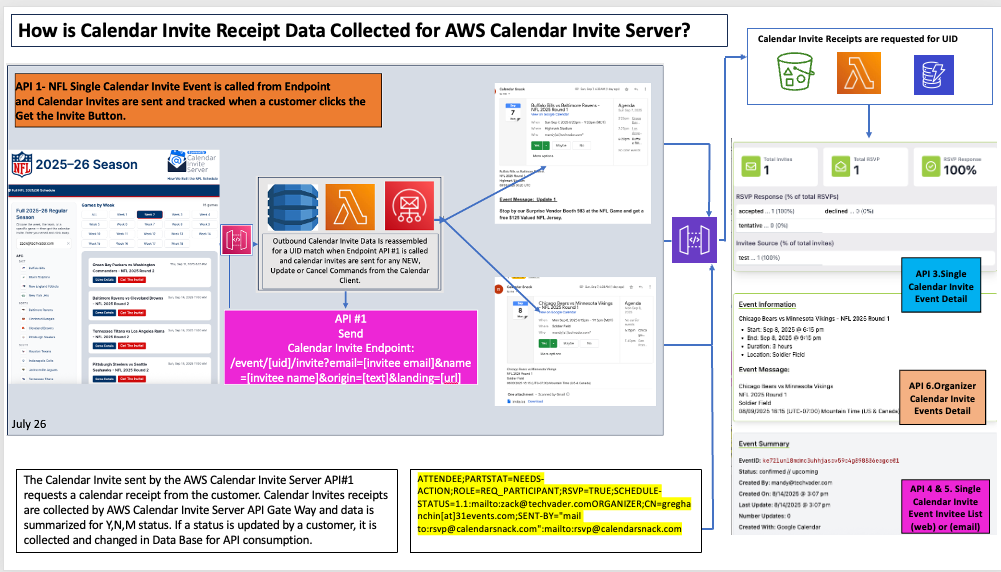
Final Storage: The resulting components are loaded into DynamoDB. Each element is stored in association with its correct Unique Identifier (UID), which serves as the primary key for retrieving and reassembling the event data later. This is achieved by using the Organizer Email Address from the Calendar Invite sent to the mailbox, and then matching the Event UID.
Once this disassembly phase is complete, the calendar data is securely stored and indexed in DynamoDB, ready for the on-demand reassembly and distribution phase.
Phase 2: On-Demand Reassembly and Distribution
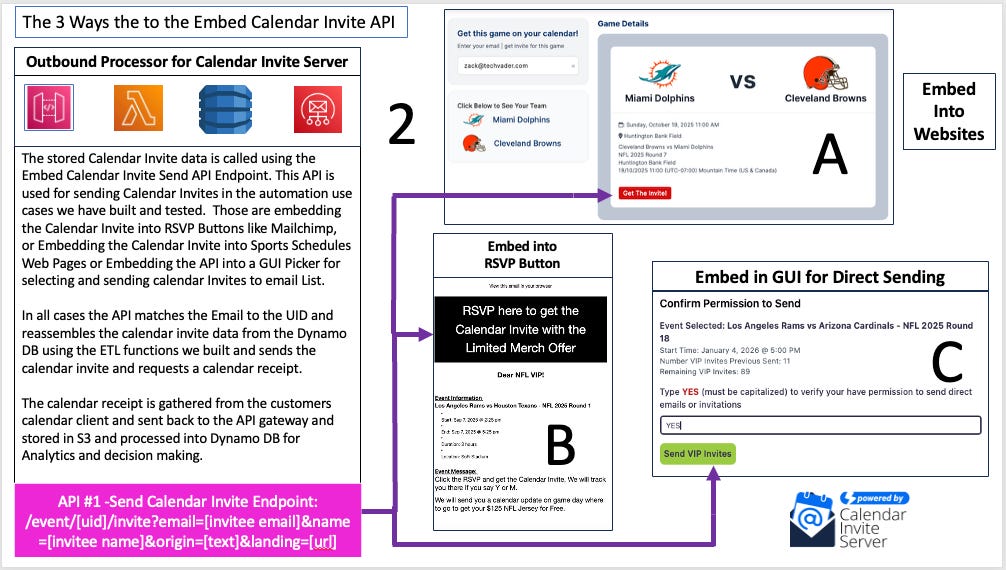
This section outlines the process of reconstructing a complete calendar invite from its stored components and distributing it to a specific recipient. This on-demand approach is highly efficient, as it generates invites only when a particular command is issued, rather than pre-generating them for all potential recipients. The command-and-control flow for this phase is executed as follows:
API Trigger: The distribution process is initiated by an API call to the "Single Event Invitation Send API." This endpoint is one of nine APIs exposed via the API Gateway and is typically triggered by a user action within the event organizer dashboard.
Lambda Execution: The API Gateway call invokes a second Lambda function dedicated to handling the reassembly and sending logic.
Data Retrieval: This Lambda function queries DynamoDB using the event's UID, which is supplied in the API request. It retrieves all the necessary parts of the calendar invite that were stored during the ingestion phase.
Invite Reconstruction: The Lambda function reassembles the retrieved components "on demand" into a complete, standards-compliant calendar invite. This ensures that the invite is always constructed from the most current data stored in the database.
Distribution: The newly recreated calendar invitation is then sent to the single target email address provided in the initial API call.
After the reconstructed invite is sent, the system's focus shifts to monitoring and persisting the status of that invitation.
Phase 3: Data Collection and Persistence Strategy
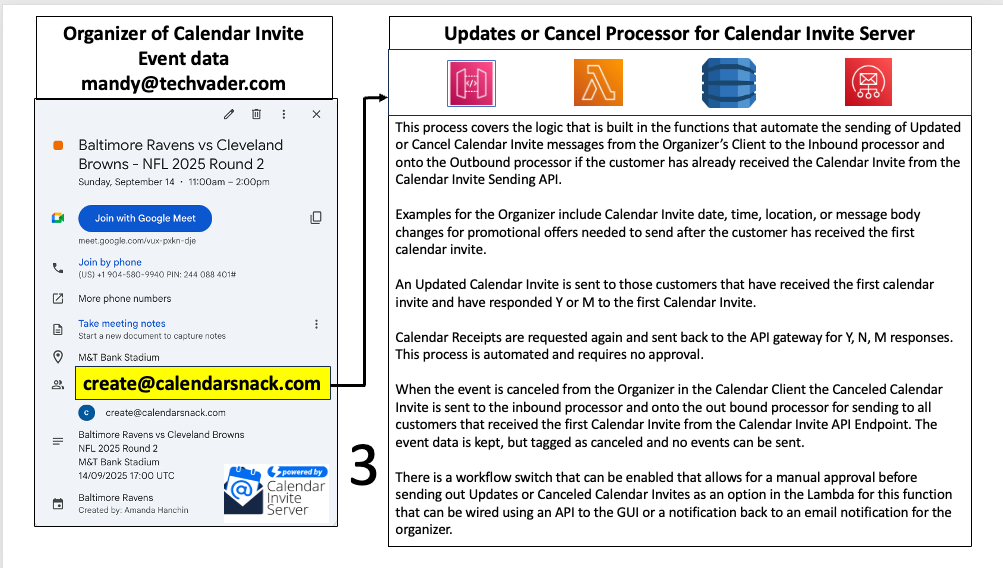
Effective post-distribution data handling is crucial for providing feedback to event organizers and for maintaining an archival record of all system activity. This final phase covers the workflow for collecting tracking data and the system's dual-layer approach to data persistence.
The data collection workflow is triggered after an invite has been distributed and response data becomes available. The sequence is as follows:
Response data is received via the API Gateway, which serves as the entry point for system feedback.
The relevant Unique Identifiers (UIDs) associated with the event are "summoned, collected, and sorted" by the system's backend logic.
This processed tracking data is then stored in DynamoDB, linking it directly to the original event data.
The system employs a dual-layer data storage strategy to ensure both performance and durability. This approach leverages two distinct AWS services, each with a specific role:
DynamoDB: This is the primary data store for the system. It holds structured, componentized calendar data and provides low-latency access for real-time operations, such as invite reassembly and status tracking. All data is indexed by its UID.
S3: This serves as the secondary storage layer. A copy of the data is also kept in S3, implying a function for backup, long-term archival, or robust logging.
With the data securely archived and tracked, the entire serverless lifecycle is complete, demonstrating a robust and scalable system architecture.
Conclusion: A Serverless Lifecycle for Calendar Data
The AWS Calendar Invite Server demonstrates a complete, end-to-end lifecycle for calendar data, managed entirely through a serverless architecture. The process encompasses every stage: initial Ingestion via email, automated Disassembly into structured components, secure Storage in a NoSQL database, on-demand Reassembly, targeted Distribution, and finally, comprehensive Tracking and data persistence. Each phase is handled by a specialized, managed AWS service, ensuring operational excellence and efficiency.
By leveraging a decoupled, event-driven model, this architecture provides a scalable, efficient, and robust solution for managing calendar invitations. The design effectively minimizes operational overhead while maximizing the ability to handle fluctuating workloads, making it a strong framework for large-scale event communication.
