


Architecting a Scalable Calendar Invitation and Tracking System on AWS
1.0 Introduction to the AWS Calendar Invite Server
Managing event invitations and tracking attendee engagement at scale demands a modern, event-driven architecture. Traditional methods, often reliant on disconnected systems and manual data entry, fail to provide the necessary scalability and visibility into engagement. This whitepaper details a serverless architecture built on Amazon Web Services (AWS) that addresses this challenge by leveraging standard calendar clients, such as Google and Outlook, as a control plane for a scalable, serverless backend. The solution provides an automated, API-driven system that streamlines the entire event lifecycle.
The core purpose of this system, referred to as the AWS Calendar Invite Server, is to ingest event data from an organizer's native client, send personalized invitations via a robust API, and provide detailed analytics on recipient engagement. This whitepaper covers both the core backend infrastructure and a reference frontend implementation, the Calendar Snack Application, which demonstrates its API capabilities. A practical example of its capabilities is the ingestion and management of the entire NFL 2025 schedule, demonstrating its capacity to handle thousands of distinct events. Understanding this powerful system begins with its high-level workflow and core architectural principles.
2.0 System Overview and Core Concepts
The system's strategic foundation is a decoupled, event-driven architecture, a design choice that ensures fault tolerance and independent scalability of its components. This approach avoids monolithic bottlenecks, allowing for the massive scale required to manage complex, high-volume event workflows. This section provides a high-level overview of the system's process—from the organizer's initial data import to the final end-user invitation—and defines the key components involved.
The end-to-end process can be broken down into four distinct stages:
Data Staging: Event data, often from external sources like
.icsFiles, is first imported into an organizer's standard Google or Outlook calendar. This serves as the single source of truth for all event information, providing us with the data to send to the calendar invitation server for staging during the NFL season.System Ingestion: A specific email command (
create@calendarsnack.com) is used within the organizer's calendar to trigger the transfer of event data from the calendar client directly to the AWS server for processing and storage.API-Driven Sending: A frontend application or an embedded web page utilizes the system's APIs to send single or bulk calendar invitations to a target audience.
Engagement Tracking: The system collects and processes calendar receipts (e.g., Yes, No, Maybe) sent back from recipients, transforming these responses into detailed analytics and reports.
Key Terminology
AWS Calendar Invite Server: The core backend system, built entirely on AWS services. It is responsible for processing, storing, sending, and tracking all calendar events.
Calendar Snack Application: A free, pre-built frontend application that provides a user-friendly interface for interacting with the server's APIs. It allows organizers to manage events and initiate sends without writing code.
Unique ID (UID): A system-generated identifier assigned to each new event ingested by the server. This UID is used to track and manage the event throughout its entire lifecycle, from creation and updates to sending and analytics.
With these core concepts defined, the next section will detail the crucial first step of the process: staging the initial event data for ingestion.
3.0 Phase 1: Initial Data Sourcing and Staging
The reliability and accuracy of the entire invitation system depend on the quality and organization of the initial data source. A well-structured source ensures that all downstream processes, from ingestion to tracking, function correctly. This section outlines the best-practice method for preparing and importing event data into a standard calendar client before sending it to the AWS server for processing.
The following steps outline the process for staging external calendar data, using the NFL schedule as a working example:
Acquire Data: The process begins by obtaining pre-formatted calendar files. For instance,
iCal(.ics) files for global sports schedules can be downloaded directly from a source likefixture-download.com. This provides a structured, ready-to-use data source.Prepare the Calendar Client (Best Practice): To manage large volumes of events, it is recommended to implement client-side data partitioning. This is achieved by creating dedicated, filtered sub-calendars within a primary Google or Outlook account (e.g., "Arizona Cardinals"). This approach to namespace management prevents data collisions. It simplifies event lifecycle management when dealing with thousands of events from disparate sources (e.g., NFL, NBA, MLB) within a single AWS server instance. It also allows event groups to be easily toggled for better visibility.
Import the Data: The final step is to use the calendar client's native import function to load the downloaded
.icsfile into the designated calendar (e.g., the "Arizona Cardinals" sub-calendar). This action populates the organizer's personal calendar with all the relevant event data.
Once the data is successfully staged in the organizer's personal calendar, the next phase is to ingest it into the AWS backend for processing and management.
4.0 Phase 2: Event Ingestion and Lifecycle Triggers
The system employs an innovative and straightforward approach to data ingestion and management. Instead of requiring complex integrations, it uses a concise, email-based trigger to control the entire event lifecycle. This architecture intentionally leverages the organizer's native calendar client as the single source of truth and primary user interface for event lifecycle management, eliminating the need for a separate, proprietary management console.
Create Command
Initial ingestion is triggered by adding a special guest to a calendar event. The organizer adds create@countersnack.com to the invitee list of a staged event and saves it. This action sends the event data to an AWS Simple Email Service (SES) mailbox. The backend system receives this email, "disassembles" the event data into its core components for storage, and assigns it a UID. The user then receives an automated email notification confirming that the event has been successfully ingested into the AWS Calendar Invite Server.
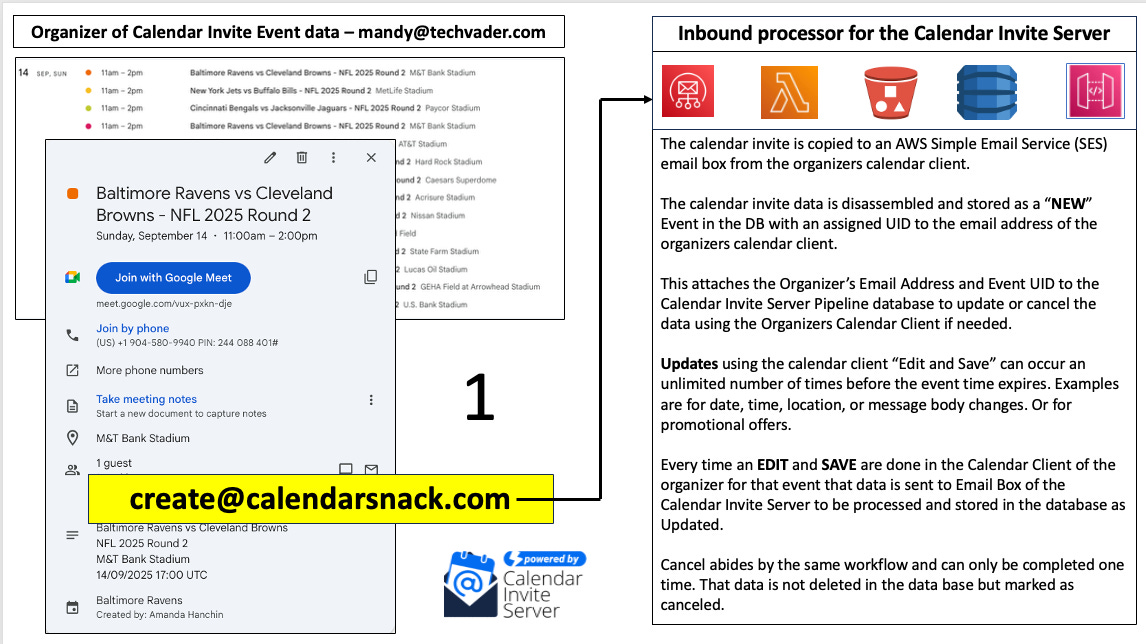
Update Command
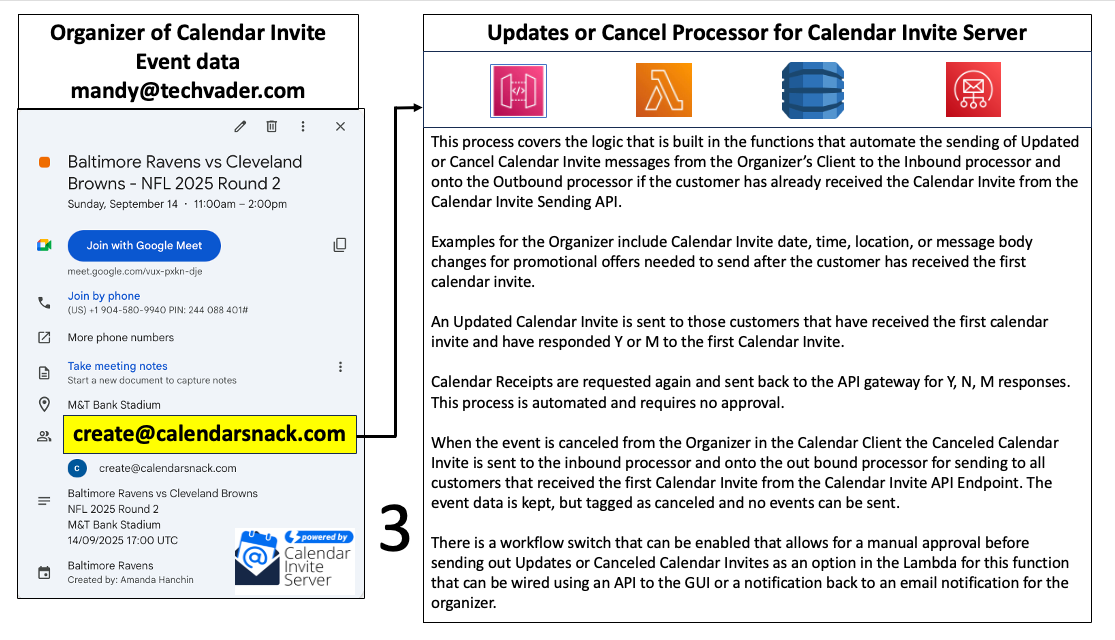
Modifying an existing event is equally seamless. The organizer edits the event directly in their source calendar—for example, by changing the start time or adding a "free hot dog" promotion to the description—and saves the changes. This saves the action, which automatically resends the event data. The AWS server recognizes the event's existing UID and processes the new information as an update. Behind the scenes, the system's storage logic treats each update as an incremental version, preserving the event's history and ensuring state is managed correctly. This process can be repeated an unlimited number of times.
Cancel Command
To cancel an event, the organizer deletes it from their source calendar. This action triggers a cancellation command within the AWS server. The system first determines if invitations for that event have already been sent. If they have, it automatically dispatches a cancellation notice to all attendees who had responded with "Yes" or "Maybe."
This elegant trigger mechanism is powered by a robust serverless backend. The next section provides a detailed examination of the specific AWS services that underpin this workflow.
5.0 Core AWS Architecture Components
The system's scalability, reliability, and rich functionality are direct results of its serverless architecture, which is composed of specific, interconnected AWS services. This design eliminates the need for managing servers while providing a robust foundation for high-volume event processing. This section breaks down the role of each key component in the architecture.
API Gateway: This service acts as the front door for all API calls from client applications, such as the pre-built Calendar Snack app or any custom-built frontends. It securely manages requests for actions like displaying upcoming events, triggering single or bulk sends, and retrieving analytics data.
AWS Lambda: As the serverless compute layer, Lambda functions contain the core business logic of the system. These functions execute code in response to triggers, handling workflows for processing new events from the SES mailbox, managing updates and cancellations, reassembling calendar invitations for sending, and listening for incoming calendar receipts from recipients.
Amazon SES (Simple Email Service): SES serves two critical functions. First, it acts as the initial ingestion mailbox, receiving event data sent via the
create@countersnack.comaddress. Second, it is the email-sending engine used to deliver the reassembled calendar invitations to end-users at scale, leveraging the SES multi-part API for robust construction of calendar event data.Amazon SQS and SNS: Amazon Simple Queue Service (SQS) and Simple Notification Service (SNS) are utilized to enable asynchronous processing and loose coupling between microservices. This is critical for managing the system's internal workflow logic and achieving the "industrial strength" throughput required for high-volume bulk sending.
Amazon DynamoDB: This NoSQL database stores the "disassembled" event data. After an event is ingested, its components are stored in DynamoDB along with its assigned UID, allowing for retrieval with single-digit millisecond latency, which is essential for the on-the-fly reassembly of invitations.
Amazon S3: Amazon Simple Storage Service (S3) functions as the data repository for long-term storage of collected calendar receipt data. This raw engagement data is archived in an S3 bucket, where it can be processed and analyzed to generate rich analytics dashboards.
With this technical architecture defined, the next section will explore the two primary application use cases that this architecture enables for organizers and marketers.
6.0 Application Use Cases and Sending Logic
The backend architecture translates directly into practical, user-facing applications that solve common event marketing challenges. The system's APIs, leveraged by the accompanying Calendar Snack application, facilitate two primary use cases: embedding one-click invitations on a web page and sending bulk invitations to an email list.
Use Case 1: Embedded Calendar for One-Click Sending
This use case allows organizers to create a dynamic, self-service invitation experience on any website or landing page.
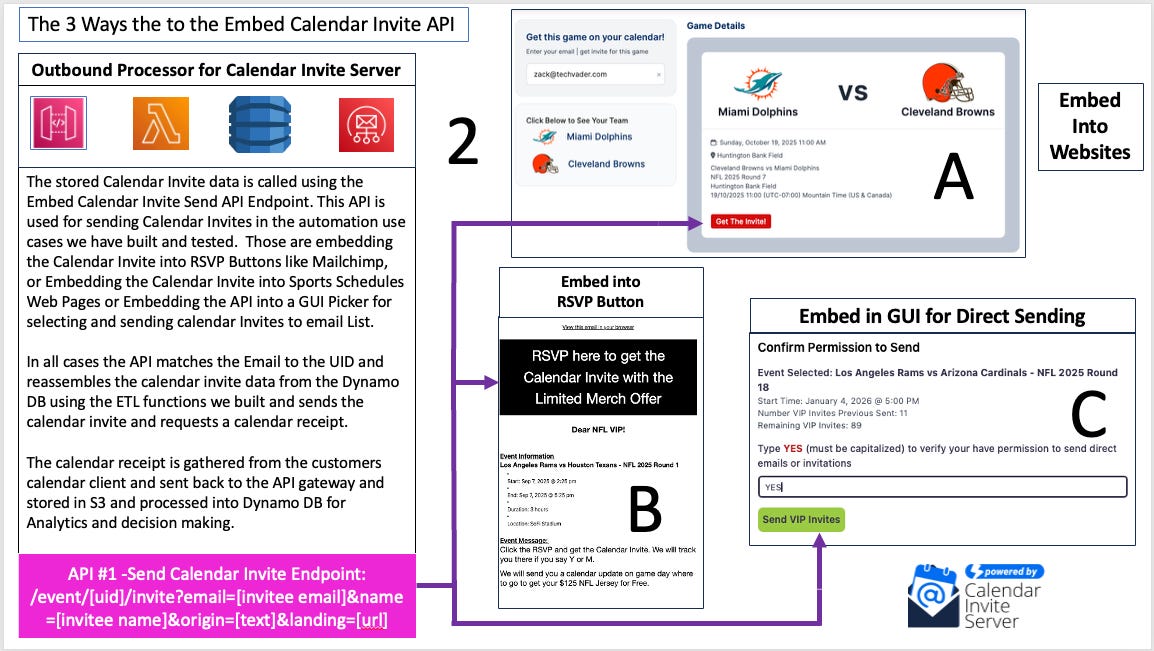
Process: The system's display APIs are used to pull all upcoming events associated with the organizer's account from the database. This event data is then rendered on a landing page, creating a schedule or list of events.
User Workflow: A visitor to the page enters their email address into a field and clicks a button corresponding to the event they wish to attend.
Backend Action: This click triggers a call to the single calendar invite send API. The API endpoint matches the recipient's email address with the event's UID to retrieve its data from DynamoDB, reassemble the calendar invitation on the fly, and send it to the user's provided email address via SES.
Use Case 2: Bulk Calendar Invites to an Email List
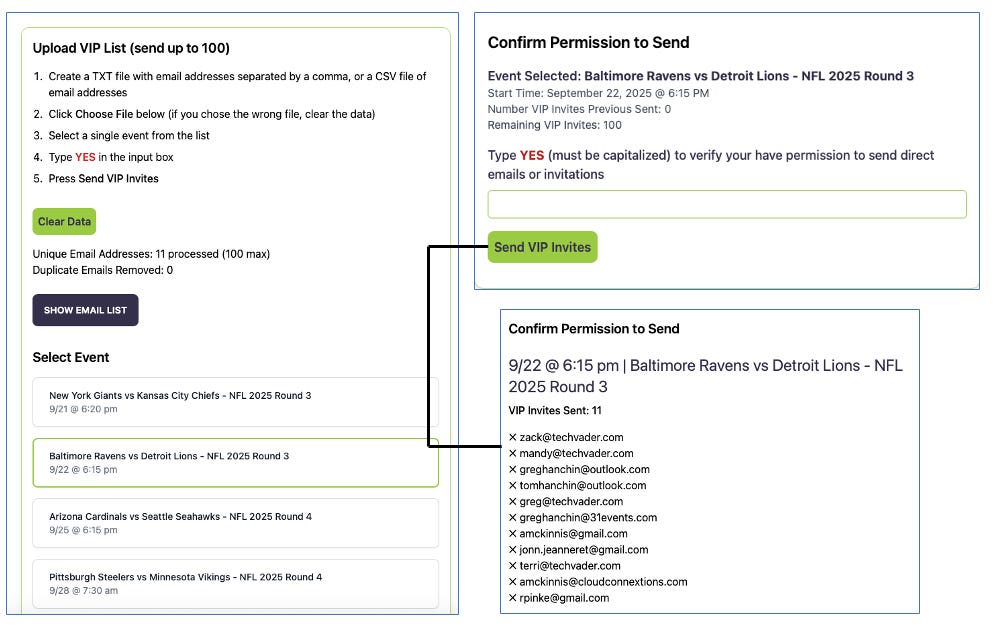
This use case is designed for sending a single event invitation to an extensive, pre-existing list of recipients, such as a customer database or marketing list.
Process: Using the Calendar Snack application, a user selects a single event to send and uploads a list of recipient email addresses.
Backend Action: The system utilizes the same core API endpoint. It iterates through the uploaded list, matching the event's UID with each email address to reconstruct the calendar invitation for each recipient. The test application demonstrates the industrial strength of the queuing and sending infrastructure by allowing batch runs of up to 100 recipients.
Beyond these primary use cases, the underlying APIs are flexible enough to support other marketing channels, such as embedding direct calendar invitation links within traditional email marketing platforms like Mailchimp. These sending mechanisms are only half of the equation; the system's actual value is realized by tracking the results, which is the final piece of the architecture.
7.0 Analytics: The Calendar Receipt Tracking Loop
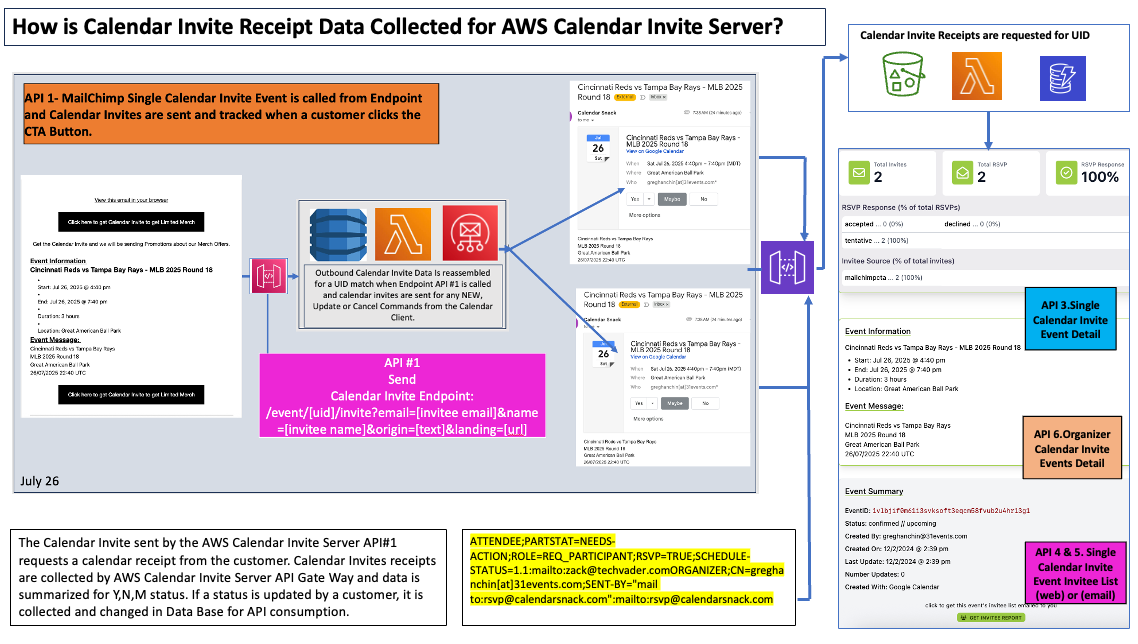
Effective event marketing requires closing the loop by tracking audience engagement. A key differentiator of this architecture is its built-in capability to collect, process, and store recipient responses, providing granular analytics that are often missing from traditional invitation platforms. This section details the architecture responsible for this powerful tracking functionality.
The core mechanism is simple yet effective: the system sends real calendar invitations that natively support responses and explicitly requests receipts from the recipient's calendar client.
A key component in this process is the Lambda Listener. This is a purpose-built AWS Lambda function explicitly designed to listen for and capture the calendar receipts (e.g., Yes, No, Maybe) that are sent back upstream by recipients' email clients when they interact with the invitation.
The data pipeline for analytics follows a clear, automated path:
The Lambda Listener collects the incoming receipt data.
This data is processed and parsed, linking each response back to the specific event and sender via the original UID.
The final, parsed engagement data is inserted into an Amazon S3 bucket for long-term archival and analysis.
The output of this process is the generation of "high definition data" that populates rich dashboards within the Calendar Snack application. These reports provide granular details of recipient engagement across all sending channels, including bulk sends and embedded landing pages, offering a comprehensive view of an event's reach and impact.
8.0 Deployment and Future Outlook
This whitepaper details a robust, scalable, and automated solution for calendar invitation management and tracking, built on a serverless AWS architecture. By leveraging native calendar clients for event management and a robust backend for processing, sending, and analytics, the system offers an elegant solution to a complex business challenge.
For organizations looking to implement this system, the path to deployment is straightforward:
Deployment: The entire AWS calendar server can be downloaded and configured in a user's own AWS account in under one hour.
Documentation: Detailed technical documentation and setup guides are available on a public GitHub wiki.
Cost Analysis: A deep-dive cost analysis for sending 52 million calendar invites per year is available at www.calendarinvite.com, providing clear insight into the operational costs at scale.
The current tech stack provides a robust foundation for today's event marketing needs and is designed with the future in mind. This architecture supports a forward-looking vision of leveraging this infrastructure for sending "calendar at scale with AI agents," promising even greater automation and intelligence in the future.
